
Glasseye
Issue 7: November 2024
In this month’s issue:
Semi-supervised looks into the problem of defining a hallucination
The tables are turned for machine learning and philosophy in the white stuff
The dunghill rails against the naysayers
Plus a logic-powered agent explores Indy World, and we finish with a useful Bayesian snippet.

Semi-supervised
I’m not sure I should thank Chris Duncan for this month’s question. So short and innocent looking - who would have thought it would turn out so nasty? The question was: “What is a hallucination?” - in the context of large language models.
The main players give straightforward answers. Google says, “AI hallucinations are incorrect or misleading results that AI models generate.” Anthropic says that hallucinations occur when LLMs “generate text that is factually incorrect or inconsistent with the given context.”
So why not just call it what it is - an error? Cynical folk will suspect a euphemism, but I don’t think this is fair. “Hallucination” might not be right,1 but I can see why a new label is needed.
This point is best made by contrasting an LLM’s output with that of an old-fashioned machine-learning classifier. The classifier learns to predict the right label for a set of inputs, the so-called ground truth. Presented with a new set of inputs the classifier gets it right if it predicts the right label. “Apple” for apple, “pear” for pear.
Now see how horribly complicated the concept of error gets for an LLM. A prompted LLM is playing a game of complete the sentence. Given a sequence of tokens (the prompt), it predicts the most likely set of tokens to follow,2 based on the billions of text chunks it has been trained on (and some additional feedback from human beings). But if we now ask whether the LLM has got it right, we run into some problems:
What is the ground truth in this case? This was straightforward for the classifier. The ground truth is the label or, if you like, the bit of the world that got labelled - in this relatively simple situation it doesn’t make a difference which you choose. But what is the LLM trying to get right? Its description of the world, or the chunk of text most likely to follow the prompt? (If you are old enough and from the UK you can imagine chatGPT as a contestant on Family Fortunes!) This distinction is most stark when we think about prompts that demand a creative response: “Write a poem about …” Here the ground truth cannot be some fact about the world. Which makes us wonder whether it ever makes sense to grade an LLM on whether it gets the facts right.
What do we mean by wrong? When we compare the predicted label “apple” and a particular fruit this is usually simple, but when comparing a chunk of text to the world there are so many more ways in which it can be wrong. It can be wrong on a minor detail that does not matter much, or it can be wrong on a detail that turns out to be crucial, or it can be mostly right, or it can be a complete fabrication, or it can just be misleading (however you define that).3 Do we have degrees of wrongness? If not, where is the line?
And if we do decide that the ground truth is the text and not the world, then we are no better off because how do we know if it has got the text right? When a standard machine learning classifier comes across some novel input (say, an image of an apple that was not seen in the training data), then whether it gets the classification right is uncontroversial. But, without referencing the world, who can say which bits of text are supposed to follow a given prompt?
When the temperature parameter is increased on an LLM more randomness is allowed to creep into the generation of the token sequence. But can a process that involves deliberate randomness truly be said to have got something right? After all, the answer will be different the next time you run it. Using the philosopher’s standard definition of knowledge as justified true belief, any correct answer from an LLM appears to lack justification. Compare this to the average machine learning classifier, which can at least justify its answer, even if that justification is often difficult to understand.
Given all this, I can well understand why someone felt that a more exotic word than “error” was needed. And it’s true that the term “hallucination” does capture the sense in which LLM output is sometimes aligned with reality and sometimes not, slipping between the two because getting the facts right was never its primary concern.
Sorry Chris, I think I have, once again, failed to answer your question, other than by saying “hallucination” is a placeholder because “wrong” does not seem right.
Please do send me your questions and work dilemmas. You can DM me on substack or email me at simon@coppelia.io.

The white stuff
An audio recommendation this month: the philosopher Tim Williamson is on the podcast The Partially Examined Life to talk about his latest book Overfitting and Heuristics in Philosophy. You can probably guess from the title why we are talking about it here! Usually philosophy is used as a tool to pick apart the more problematic areas of science - statistics, data science and AI included. But here Prof Williamson turns it around and applies a concept very familiar to us - overfitting - to philosophy itself. This is the man who managed to convince most contemporary philosophers4 that there is a sharp but unknowable boundary between a bald person and a person with hair. It cannot be anything but interesting!
On the topic of overfitting thanks to Simeon Duckworth for forwarding me the paper Questionable practices in machine learning after reading the July issue. Machine learning is my happy place when I get frustrated with all the fakery in statistics so this sobering.

The dunghill
It’s true; we’ve been a bit hard recently on people who like to say yes. We’ve tended to lump them together with all kinds of deluded, eager-to-please go-getters. This month we will even things up - saying yes is not a sin and indeed the naysayers have a bullshit of their own.
A recent recipient of the “no” variety was a client of mine. She explained how frustrated she was with her internal data science team. Nothing would move forward; every project she proposed would come to a halt on the pretext of inadequate data or unmet modelling requirements.
Now to those who say, in response to a data set and a question, it can’t be done, I say this (full-on preacher mode now): here is some data; here is the question; and sitting between the two is a system - mechanical, biological, economic, social - that both generated the data and motivated the question. Your job is to explain, as best you can, how the data relates to the question, even if the answer is that there is no relation. This is usually extremely difficult and might require no end of caveats, but it is rarely impossible, and it should be a point of honour that you at least try! All the statistical and algorithmic tools we have exist only because this problem has been cracked in a small number of cases.
So by all means say, "This can't be done using linear regression," or "There's an entire PhD's worth of work here," or even, “I don’t know how to do this; we need help,” just not that it cannot be done.
This extends to the problem of bad or incomplete data. Whoever or whatever is responsible for the badness must be considered part of the system that generated the data - and so part of this ever more intriguing problem.
We could put it another way: as a statistician you need never say no. Quantifying uncertainty is your trade. If your first objection is, “This will be wrong,” then the next question you should ask is, “How wrong will it be?” And if even that is unanswerable then your fallback task is to show why it is unanswerable and therefore what can be done to fix it. We always have something to say.
And how do we solve these very hard problems - the ones that do not fit the templates of those already solved? Each one is different; I can only offer tips. Simulation is a godsend since it allows you to experiment with (and sensitivity test) complex assumptions. Solve the problem first for simpler “toy” systems and work your way towards the real world. You may need to go back to first principles and invent new things. And my favourite - divide and caveat: make your results conditional on some clearly stated assumptions about which the client must make a call. There is nothing wrong with a conclusion that takes the form: if this then that. After all, you can’t do everything.
If you have some particularly noxious bullshit that you would like to share then I’d love to hear from you. DM me on substack or email me at simon@coppelia.io.
From Coppelia
Indy world
I’m very proud to present you with Indy World, a knock off of the famous Wumpus World popularised by Russell and Norvig in Artificial Intelligence: A Modern Approach (still my favourite AI textbook). Wumpus World was too complex for my needs (a short training session on symbolic AI) so I paired it down by killing off the Wumpus. We are left with something very like the opening scene in Raiders of the Lost Ark. Indy must cross the temple floor to retrieve the idol while avoiding the pits. He knows he is near danger when his flaming torch flickers in the breeze coming up from a pit. He knows he is near the idol when his torch lights up the steps.
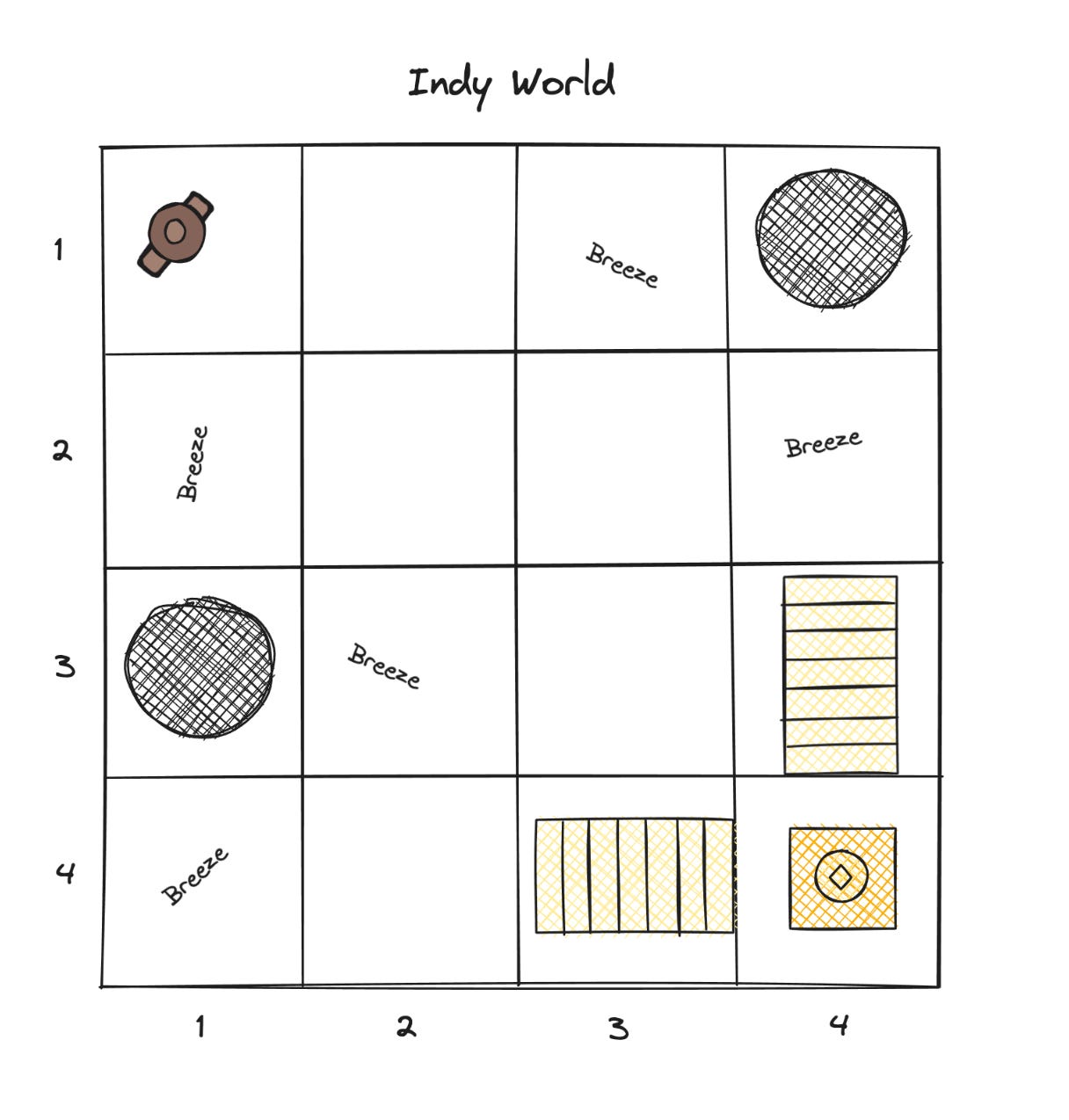
Here’s the code if you’d like to see how an agent solves this using just propositional logic.
Bayes with boundaries
Here’s another useful snippet from this month’s workload. Quite often we want to estimate a population proportion from some sampled data using an informative prior because we know a priori the upper and lower bounds for that proportion. If we assume that the prior distribution is uniform between lambda (the lower bound) and mu (the upper bound) then the posterior distribution is defined as:
Where C is a normalising constant.
This is very easy to simulate (no need for pymc):
import numpy as np
def bayesian_proportion_with_informative_priors(n, k, lam, mu, n_samples=1000):
p_grid = np.linspace(lam, mu, 1000)
unnormalized_posterior = (p_grid**k) * (
(1 - p_grid) ** (n - k)
)
# Normalize the posterior
posterior = unnormalized_posterior / unnormalized_posterior.sum()
# Sample from the posterior distribution
dist = np.random.choice(p_grid, size=n_samples, p=posterior)
return distIf you’ve enjoyed this newsletter or have any other feedback, please leave a comment.
Strictly speaking it does not always output the most probable tokens. As the temperature parameter is raised the the LLM starts to sample tokens using the predicted probability distribution.
The authors of this preprint identify several interesting categories
On the analytic side of the fence that is!