
Glasseye
Issue 2: June 2024

In this month’s issue: ritualised A/B testing reaches new depths in The dunghill, Semi-supervised looks at how to disarm meeting room alphas, and The white stuff revisits the prophetic work of Hubert Dreyfus.
That, a new measure for correlation, a moan about about synthetic respondents, and some new toys in my toy box.
That’s surely enough to be getting on with…

Semi-supervised
I was asked this month’s question during a data science mentoring session. It’s quite a common question so I’ve distilled its many variants into the following:
What is the best way to deal with those aggressive alpha types who stalk the upper levels of a corporation, and who are intent on pulling apart your presentation in front of everyone else, either to impress their boss or just for the sheer hell of it?
Let’s get specific about the kind of pain that is meted out. My guess is that this person:
Points out humiliatingly simple objections to your findings.
Takes control of the narrative, asking you to flip backwards and forwards between slides, until everyone, including you, is quite lost.
Has a strong opinion about your area of expertise, based on a skim-read of some LinkedIn posts. Nevertheless, since this gives him - I am going for the more likely gender here - a little more knowledge than the rest of the room, it’s him against you, and he pulls rank.
Punctuates your presentation with comments like “Why is this interesting?”, “How is this relevant to the business?” (all of which he got from The Apprentice) or, to signal the utter worthlessness of your contribution, simply gets out his phone.
I’m assuming that a macho face-off is not an option. It never was for me. But there are other ways to get what you want. Here’s my advice:
When you present your results, deal with the most obvious objections first, and in the order in which they would occur to someone approaching the problem for the first time: “You would have thought it would be like this [slide] but no… it’s actually like this [slide]… but isn’t X being caused by Y? Well we looked at this and in fact [slide]” This should proof you against those humiliatingly simple objections, and give you back control over the flow of the slides - the argument will be marching forward at such a pace that he, like everyone else, will be focused on keeping up.
To make sure your argument is watertight, re-read your presentation or report, imagining that it has been written by someone you hate so much it hurts. Look for inconsistencies in the numbers, ratios that don’t make sense, percentages that could not possibly be true.
Now for the judo move. This is the way to tackle his favourite but quite wrong theory on how things should be done. The trick is not to confront it head on. Instead pretend that you are unaware that this is his view. Mention it briefly, causally, as the view only a rookie would hold. It’s an industry joke, a favourite cautionary tale for data scientists; it certainly never crossed your mind that anyone here would believe such a thing. This works because it raises the stakes considerably for the bluffer. Defending an often ridiculed position he risks looking an utter fool. Yes it is pure sophistry, but we’re allowed to do this too.
Finally, to proof yourself against the charge of irrelevance, don’t be afraid to relate your findings back to the things that matter to your organisation: more likely than not, this means revenue or profit. The link between your findings and an increase in revenue might be quite tenuous, it might involve many assumptions, but as long as you spell these out clearly and highlight the uncertainties then you are entitled to make that link. When there’s cash on the screen, the phones will go back in pockets!
Please do send me your questions and work dilemmas. You can DM me on substack or email me at simon@coppelia.io.

The white stuff
Daniel Simpson at TJX Europe alerted me to this paper by Sourav Chatterjee which proposes a new measure of correlation that avoids the well-known deficiencies of Pearson’s correlation coefficient, Spearman’s ρ, and Kendall’s τ.
His goal is “a coefficient that approaches its maximum value if and only if one variable looks more and more like a noiseless function of the other”.
You can judge how well he does with this in the chart below. There’s no doubt that it’s impressive.
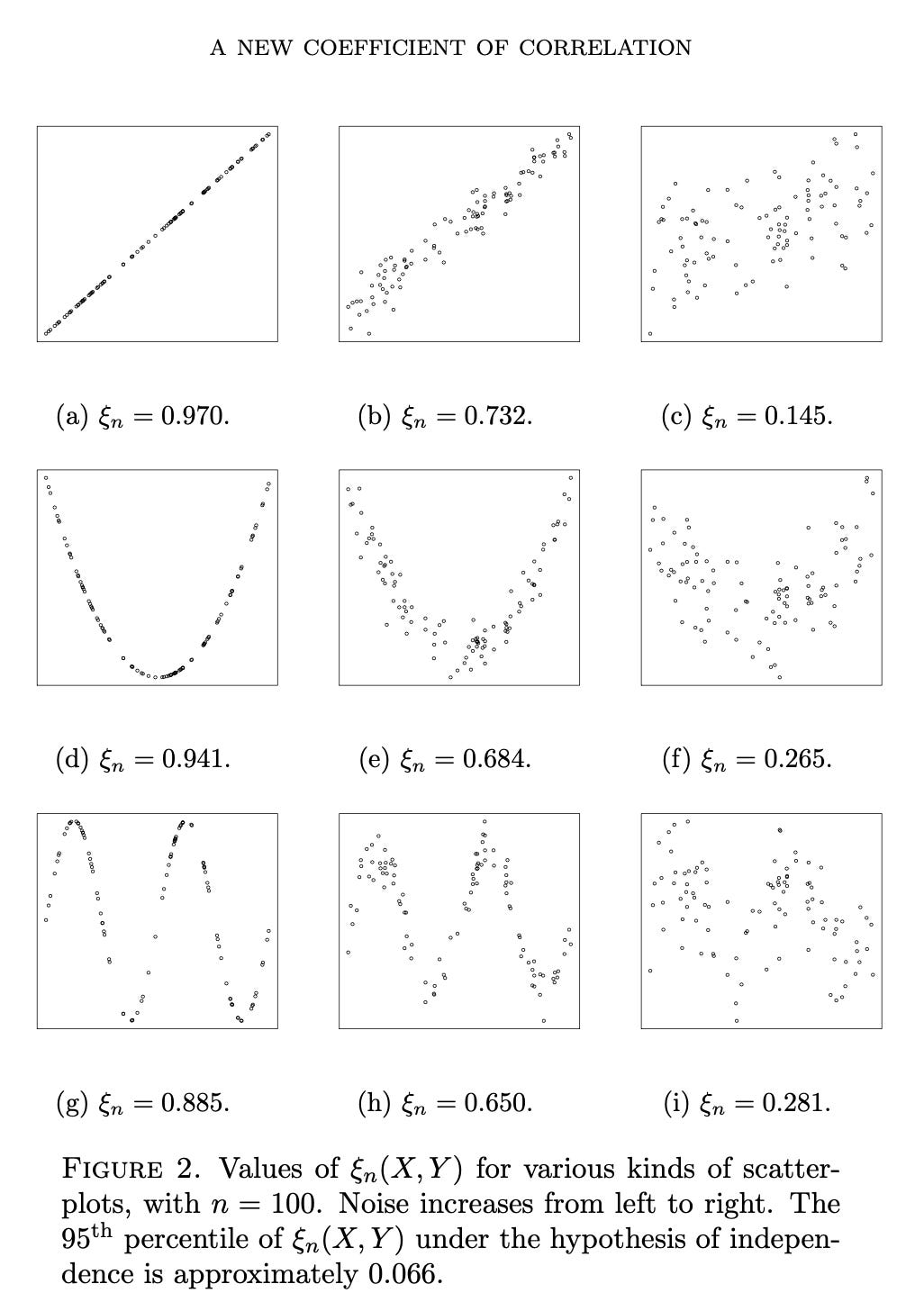
Reading the paper, I particularly like the way he spells out the difference between “coefficients are designed for testing independence” and coefficients that are designed “for measuring the strength of the relationship between the variables.” A distinction that is not made enough. What’s particularly nice about his ξ coefficient is that it does both.
A python package for implementing Chatterjee’s ξ can be found here.
The late Hubert Dreyfus, a philosopher at Berkeley, wrote a series of devastating critiques of AI in the seventies and eighties. He came at it from an unusual angle (his interpretation of German and French existentialist philosophy) but this allowed him to see something his contemporaries could not - the fact that human-like intelligence can only come about through being embodied in the world. This is an especially pertinent insight right now, as we are starting to see the shortcomings of LLMs. He also pointed to a solution: “If the body turns out to be indispensable for intelligent behavior, then we shall have to ask whether the body can be simulated on a heuristically programmed digital computer. If not, then the project of artificial intelligence is doomed from the start.”1
What Computers Can’t Do is available on the Internet Archive (an amazing site if you’ve never been there). For a retro treat you can also watch Dreyfus on the Bryan Magee programme. Nothing to do with AI and everything to do with seventies suits and TV before it was patronising!

The dunghill
To show a higher-than-average level of sophistication in your understanding of A/B testing, arch an eyebrow and say something like, “Well of course, in our case the costs of a false positive are negligible”. Well done. You have demonstrated that you understand the importance of weighing false positives against false negatives.
But do you really believe this? If you do, and you also believe the cost of a false negative is substantial, then the obvious move, as any scammer will tell you, is to spam everyone. And if that’s your plan then you don’t need to run an A/B test.
But if that’s not the case - and it rarely is (even the scammer loses in the long run by drawing attention to the scam) - then keep the testing and do it properly by working the costs into your calculations. This you can do by planning a test that delivers an alpha value (the probability of a false positive) and a beta value (the probability of a false negative) that reflects the respective costs of those outcomes.
But to carry on testing while ignoring the results on the grounds that false positives aren’t worth bothering about - this is verging on madness. Nevertheless, this was exactly the experience of a data scientist I spoke to recently.
At his company, he explained, it was never in doubt that new product features were going to be implemented, and yet still the tests took place. Deprived of any real role in the decision-making process, the tests became empty rituals, and like most rituals they became weirder and more elaborate as time went on. From the start, those tests in which an A/B test yielded a p-value less than 5% were labelled “significant”. Not unusual. But soon after this a new label appeared: “soft-significant” covered p-values from 5% and 45%. Finally, to give full coverage, those higher than 45% were labelled “not significant but implementable”. The most coveted label was obviously “significant”. Fortunately obtaining this label was made easy since the product owner (not the data scientist - the testing tool was “self-service” to bypass the data scientist’s sage advice) could pick a metric from around 50 or so after the test had run. In other words the tool strongly encouraged HARKing.
The craziest thing about this situation, as the data scientist pointed out, is that the false positives were not harmless. A new product feature could just as easily have displeased a customer as pleased them. And even if a feature was wholly unobjectionable, there’s the opportunity cost brought about by not implementing a better feature. This was the worst of all worlds. A pointless, soul-destroying process was introduced exactly where an effective one was needed. And why? Probably because someone somewhere higher in the chain needed to swing their stats credentials.
If you have some particularly noxious bullshit that you would like to share then I’d love to hear from you. DM me on substack or email me at simon@coppelia.io.
From Coppelia
Thanks to Molly Devine, Barry Watson and the team at the Economist for enduring eight hours of me talking about statistical inference, causation and Bayesian statistics! You in particular might be interested in the first paper in this month’s The white stuff. Anyway, I really enjoyed it. I hope you did too!
Do you like our owl?
You can find here my slightly world-weary contribution to the MRS report on the use of LLMs to generate synthetic survey respondents. I’m not sure on reflection that I was aiming at the right target: I doubt anyone will bother to dress up the results in statistical regalia. The bigger issue is what the LLM-generated data represents. At best it is like being handed a survey without being told where the information came from, and I don't have a lot of faith in people holding that thought in the back of their minds when some interesting and favourable result crops up. The most depressing thought though is that there will doubtless be no shortage of buyers and sellers, and very little incentive to check whether the findings are true. See here for a sample of the growing hype.
New toys
Understandably clients don’t want their data passed through to the OpenAI API so I’ve begun experimenting with self-hosted LLMs. Ollama (thanks for the tip Duncan Stoddard) makes installing and interfacing with llama 3 a cinch. I’m using langchain to pass through prompts. The results are ok but even on my over-powered Mac the problem is speed. Takes around a minute to respond to each prompt. To do anything seriously I will need to build a pc. I’ll be looking for some tips from Jens Moller-Butcher.
I can report that the Whisper Transcription app from the app store is a nice easy-to-use interface for the OpenAI audio transcription models. Even using the small model the results are amazing. Larger models require a subscription so it might be more economical to use the API directly.
Everything I produce for clients - presentations, reports, demos now comes out of Quarto (thanks to Simeon Duckworth and Andrie de Vries for pointing me in this direction) but it’s still a struggle to do custom formatting on pdf output. I’ve started looking at Typst as an alternative to Latex. It looks very promising (especially the scripting) and is also supported by Quarto.
If you’ve enjoyed this newsletter or have any other feedback, please leave a comment.
Dreyfus, Hubert (1979), What Computers Can't Do, New York: MIT Press, p. 147.
Glad to read you are embracing Quarto, Simon. I never stop looking for opportunities to use it!